������Ӧ���ܹ������������ǵ�����Ȧ����һЩ�߿������˵����±�ˢ����Ҳ�����кܶ��ѧ�Ա���Щ�������������ˣ���ʵ���Ǻ���ܴ�̶ȵ�����֪ʶͼ����صļ�����
�����ҵķ�����Ϊ�������֣�
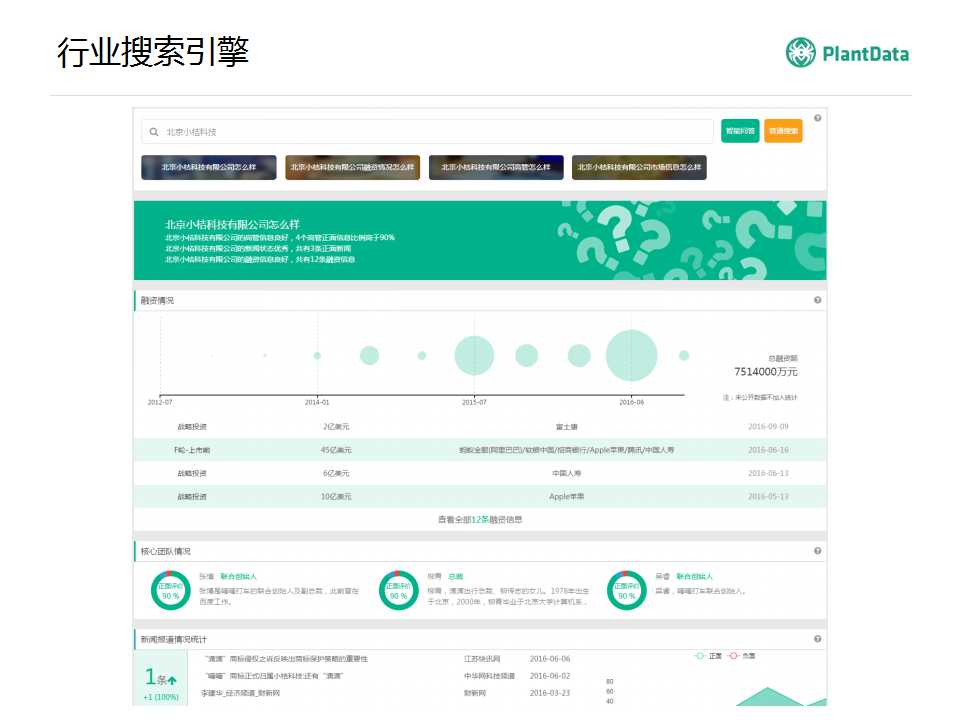
��һ�����Ƕ�֪ʶͼ��֪ʶͼ��Ӧ�õļ�����һ��������Ȼ���Ƕ�����Ӧ��֪ʶͼ������ҵ�����ݷ����һЩ̽����


�������ǰ��չ�������һ��ʲô��֪ʶͼ�ף����������õ���������֮����һ�仰������������һ���������ݵĻ���������ij�ֺ�������˵������ʵ����һ��ȫ�ֵ����ݿ⡣
ʲô��һ���������ݵĻ�������
���Ƕ�֪�����������ǿ�������վ������˵�������ĵ�����ҳ��һ����������������������м䣬������Ҫ��Ϣ��ͨ����ҳ������ģ���ҳ����֮�������ڱ����������⣬����ƽʱ���Dz�����Ϣ���DZȽϷ���ģ���������һ��ȱ�㣬����������Ϣ���㣬���Ի������������Ƚ����ѣ��������ǵĻ���������ת�䣬����ת���Ϊһ���������ݵĻ������������ֻ��������棬������Ϣ�������ǿ��Ա���������ġ�
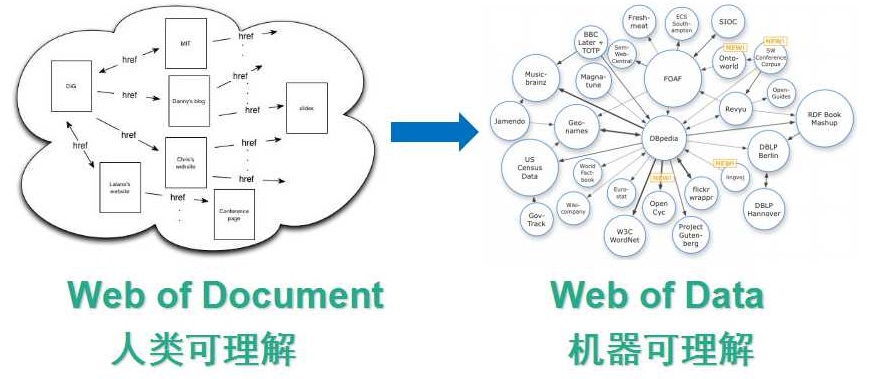
���ǿ�һ��ʲô���������ݵĻ��������������ǵĻ������м䣬����Ӧ��ֻ��һ��������ҳ����Ӧ�ø������һ�������������˵��һ������ʵ�壬�����������ͼ�м俴���ģ���������������ĸ�����Ƕ���Щ�������������������ͼ��������˽������ǹ�����ѧ�����������Ʒ�ȡ�
������������ݵĻ������о���������Щ���ﱾ�������ǹ����ģ���������������������Щ����֮��ĸ��ָ����Ĺ�����ϵ�������˵���������ݵĻ������ı��ʣ������и��ָ��������Ȼ������Щ����֮��Ĺ�����ϵ��
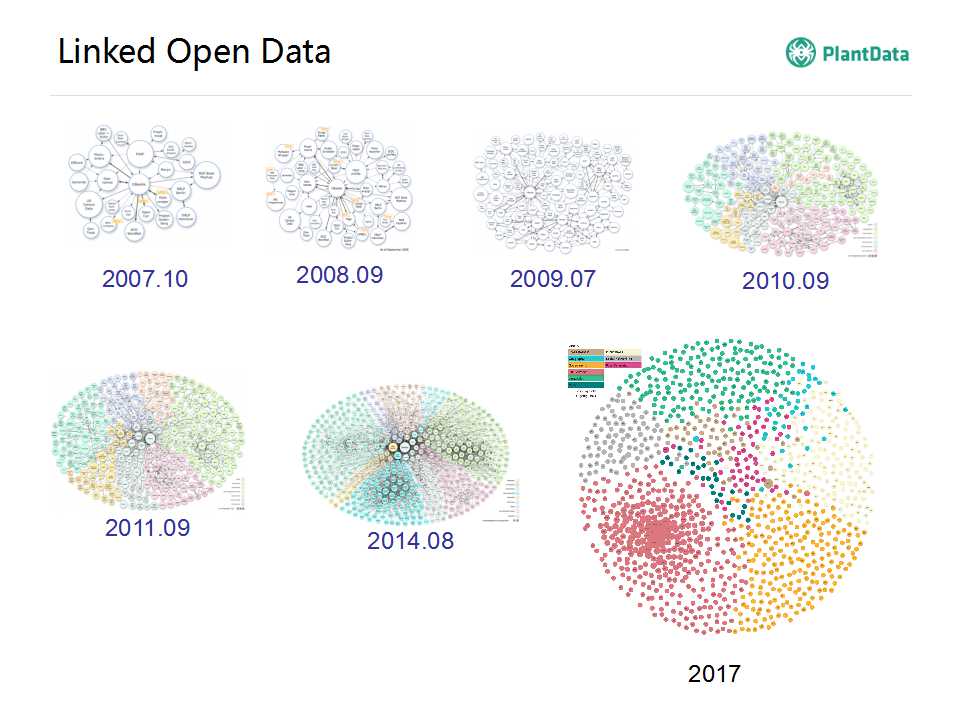
����������һ�£�Ϊʲô������������ݵĻ���������һ�������07�����ҿ�ʼ�����ǿ��Կ�����������������Խ��Խ�࣬���ͼ��07�굽���ڣ�������10�����ҵ�ʱ�䣬���ǿ��Կ������ķ�չ�Ƿdz���ģ���������ڲ��ϵ����ӡ���Щ���������˵���ǽṹ����������ģ���һ������������
����һ�������棬Google��12���ʱ�������“֪ʶͼ��”�ĸ���ո�����ʦ�ᵽ��Google��Ҫ������������һ�����������棬Google���֪ʶͼ��ʱ��������ôһ���̾䣺
Things, not strings!
Ҳ����˵���ڻ�������������һ�����ַ���������һ������ʵ���ڵ��������֮�仹����Ӧ�Ĺ�����ϵ�����½�ͼ���ǿ��Կ�����������������һ�������֮��Ĺ�����
ʲô��֪ʶͼ�ף�
��ʵ�����Ƿdz���ģ��������ṩһ�������Լ������⣺֪ʶͼ����Ҫ��Ŀ��������������ʵ�����м���ڵĸ���ʵ�����Լ�����֮��Ĺ�����ϵ��
�����ʼ��ʱ��Ҳ�ᵽ�ˣ�����һ��ȫ�ֵ����ݿ⣬�����ȫ�ֵ����ݿ��м䣬�����ϣ�������е����ﶼ��һ��ȫ��Ψһȷ����ID��������ҳһ����ÿ����ҳ����һ��Ψһ��url����ʶ����ÿ��ʵ��������Ҳͬ��������ôһ��IDȥ��������֮Ϊ��ʶ����
ͬʱ������Щʵ�壬���ǵ����ԣ����Ǿ���“����–ֵ��“���̻������������ԣ�����˵���ǵ�����������䡢���ߡ��������ԣ�ͬʱ���ǻ��ù�ϵ����������ʵ��֮��Ĺ�����
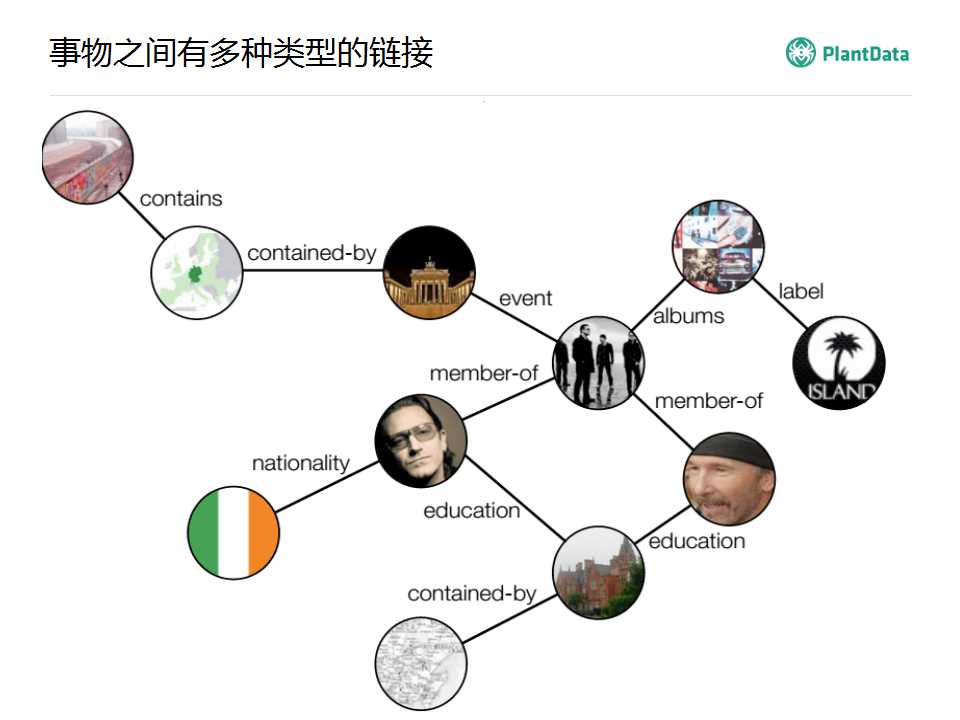
����������ͼ�������������������֮��Ĺ�ϵ��

֪ʶͼ�ĸ���DZȽ���ȷ�ģ������кܶ����ѻ��ǻ�������ʡ�
֪ʶͼ�ͱ��嵽����ʲô��ϵ��
֪ʶͼ�ײ�����һ��ȫ�µĶ�������������ǰ�ļ������������棬���е�һ�����µĶ��壬������һ���µĸ��
֪ʶͼ�ױ������DZ����һ�����Ʒ�����ڱ���Ļ�����������һ���ḻ�����䣬����������Ҫ������ʵ����档������ͻ������Ҫ�Ǹ������֮��Ĺ�����ϵ����֪ʶͼ����������Ҫ��ʵ�壬����Щʵ������ͨ������ȥ���������ӷḻ����Ϣ����һ��Ļ���˵���ǣ�����������֪ʶͼ������ģʽ������Ķ�̬�����Ը�����֪ʶͼ��̬����ģʽ֧�ֵ�������
��һ���Ժ���Ҫ�����������Ǻܶ�ĵط�������˵������Linked Open Data������õ����������ͬʱ�����ᵽ���ں�����ҵ�����ݵ�Ӧ�����棬��ʵҲ���õ�������ԣ�������֧�����ݶ�̬��Ǩ��������
֪ʶͼ������Щ��;��
���������о���һЩ����Ҫ���˹�������صģ���Ϊ�����˹����ܷdz��𱬡�
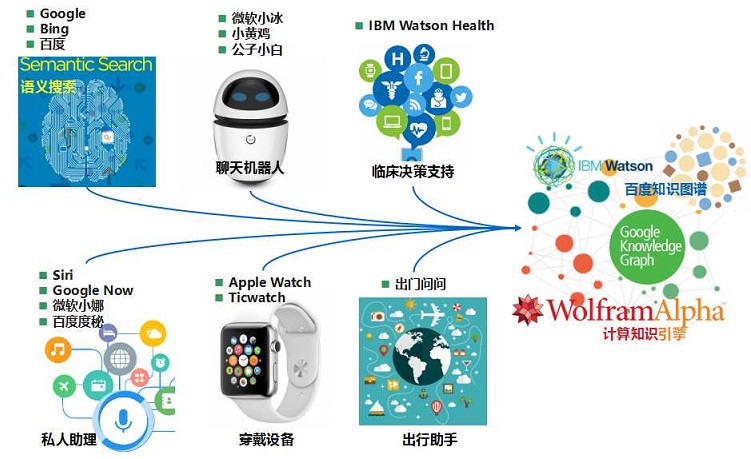
��һ������������������Ҳ��Google���֪ʶͼ�ij��ԣ��ڶ���������������ˣ������������ĸ�λ�����ٶ����ù�������˵����С������껷���ʦ��˾�Ĺ���С�ף������������������ʴ���һ�����dz���ģ�����IBM Watson������ҵ�ڷdz�������Ȼ�����ڻ��кܶ�˽�˵�����������˵����ƻ���ֻ����Siri����������С�ȣ��ٶȵĶ��أ�ͬʱ���ǻ��кܶ�Ĵ����豸��������Ҳ�õ���֪ʶͼ����صļ���������iWatch��������ˣ����һ���������dz��е����֣��������ķdz��õ�“��������”����Ҳ��������صļ�����
�����Ƕ�֪ʶͼ����;��һ���Ľ��ܡ�
��������������֪ʶͼ�ĵ�һ��Ӧ�ã�Ҳ����֪ʶͼ������ij���——��������������
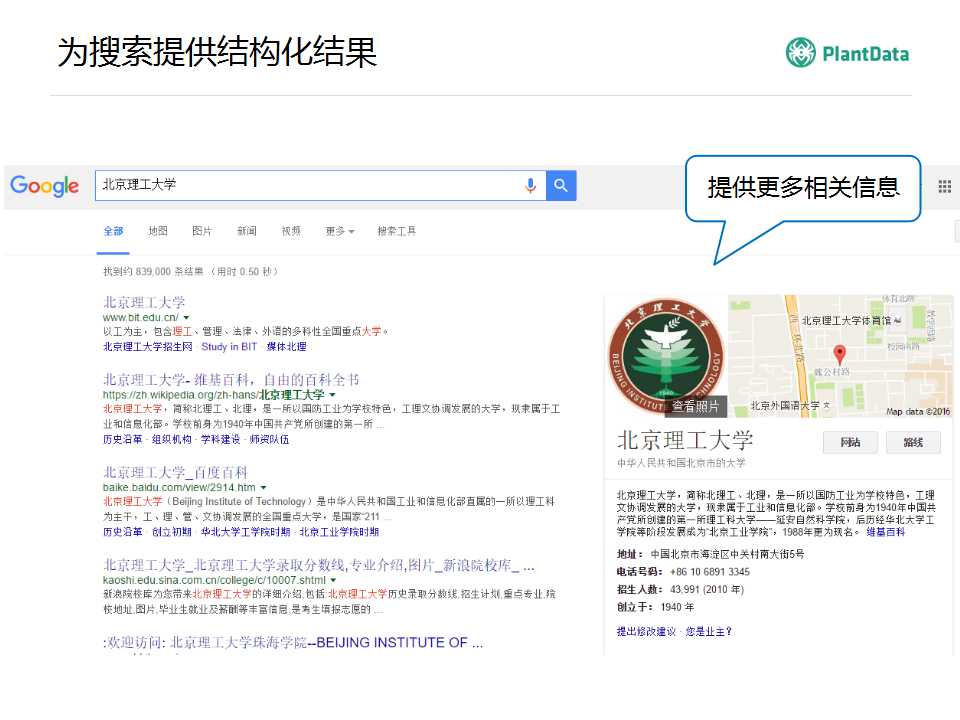
�����������ȥ Google �ѱ���������ѧ��ʱ�����ǿ��Կ����ұ���һ��֪ʶ��Ƭ������������˱������ĺܶ�������ܣ�ͬʱ����һЩ���������ԣ�����֪ʶͼ������������������Ǵ����ĵ�һ���仯��
����������ðٶ���һ�£��ܶ����ѵ�ʱ����ܻ��룬���Ҫ������������ѧ�����Ҫ���ٷ֣�����������Ҳ�Ǹ߿���ʱ�䣬���������ѵ�ʱ����Կ������ڲ�ͬ���������������Ķ�λ���Զ��ѱ������ڵ�ǰʡ��ȥ�ꡢǰ���ǰ�����һ������չʾ������ͬʱ����Ҳ���Կ���һ����ͼ����ͼ�������Ǹ����㱱������ʲô�ط���
ͨ��֪ʶͼ�ף���������������������Կ����ḻ�Ľ�������ұ����ǿ��Կ����ͱ�������صĸ�У���Լ��ͱ�������ص�����һЩ��������֪ʶͼ�����Ǵ����������ĸı䡣
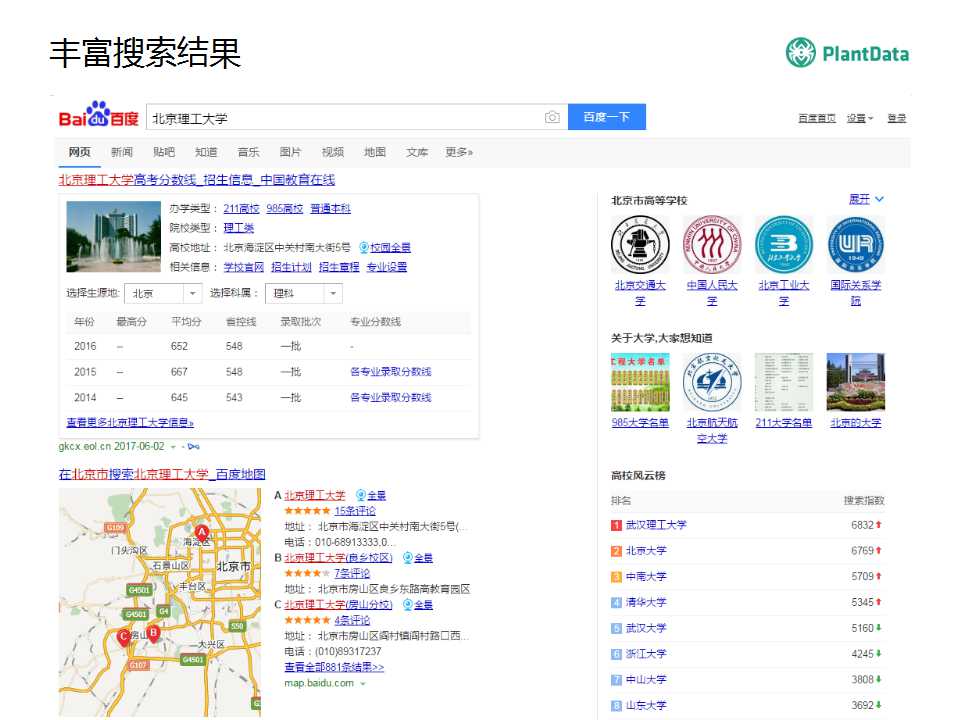
ͬʱ���ǻ����Կ�����������������棬��������һЩ�ṹ������Ϣ�������кܶ�����Ĺ�ϵ��
��������ȥ��SuperCell��ҹ�˾������һ����Ϸ��˾�����ǿ��Կ������ĺܶ��������Ϣ������CEO��ĸ��˾��������ַ�����DZ���Ѷ�չ���һ�Ҵ����ں����Ĺ�˾��
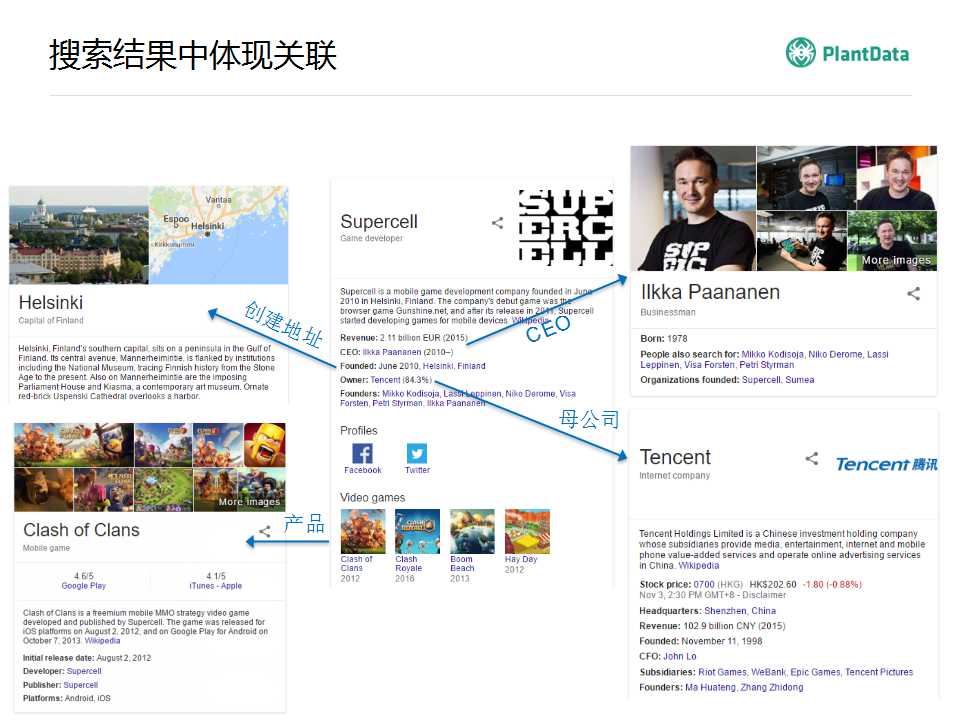
�����������������棬���罻������Ҳ�õ���֪ʶͼ�ף�����ù�Facebook����������֪ʶͼ�ļ���ȥ�������������ص���¼����������Ǿٵ��������ӣ����ȥ��ϲ�������ѧ���ˣ�������ֱ�Ӹ���𰸣��ڶ������ӣ���ȥ�������ѧ���ˣ���ͬ�����Ը���𰸣�
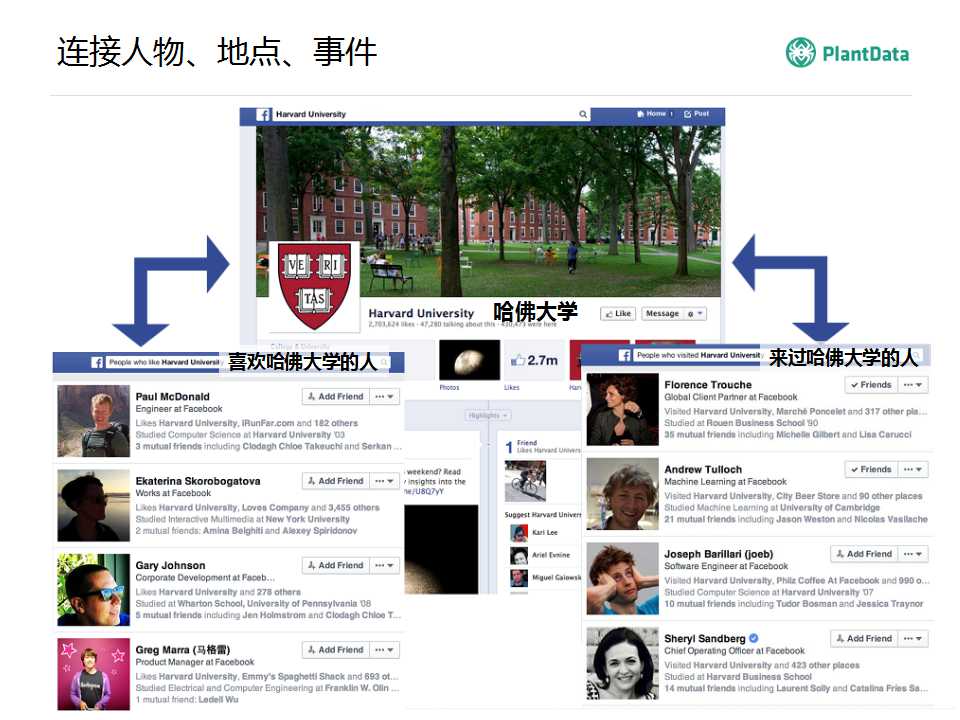
��������罻���������Ӧ�á�
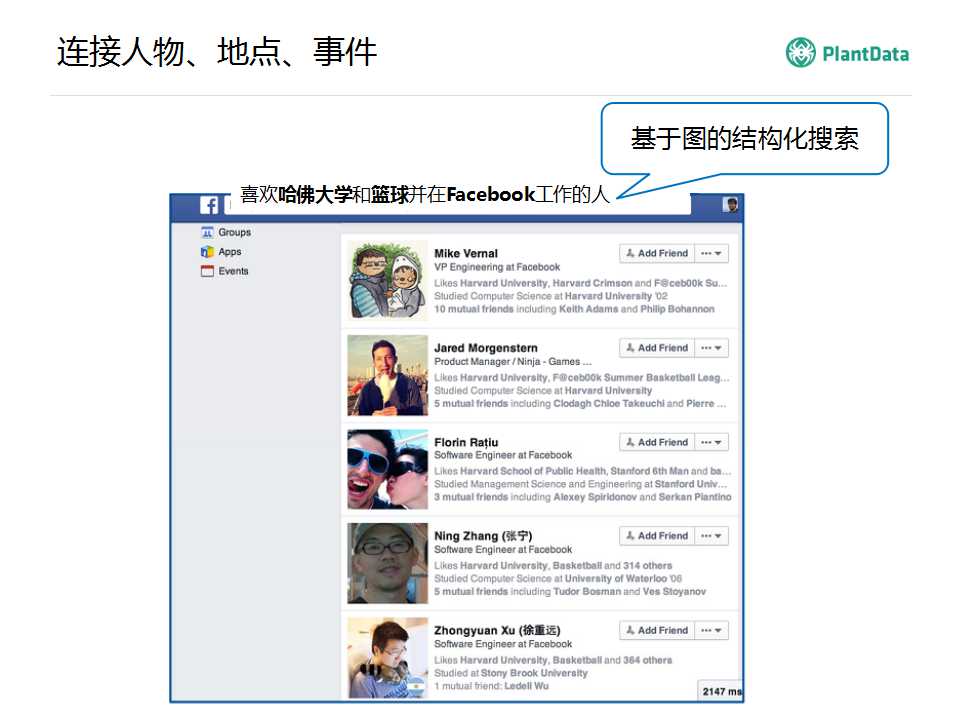
�ٿ�����һ�����ӣ�������Ӹ��Ӹ��ӡ�
�����ȥ��ϲ�������ѧ��ϲ����������Facebook�������ˣ�����ʵ��һ���Ƚϸ��ӵ��������������ǿ���������һ���ʴ���Ҳ��֪ʶͼ���ܹ������Ǵ����ĸı䣬Ҳ�������ѵ�ʱ��ֱ���ܹ�����𰸡�
��������ͨ��֪ʶͼ�����罻����������ЩӦ�ã�����ҵ��Ҳ�����Ƶ�ʹ��֪ʶͼ�����IJ�Ʒ��
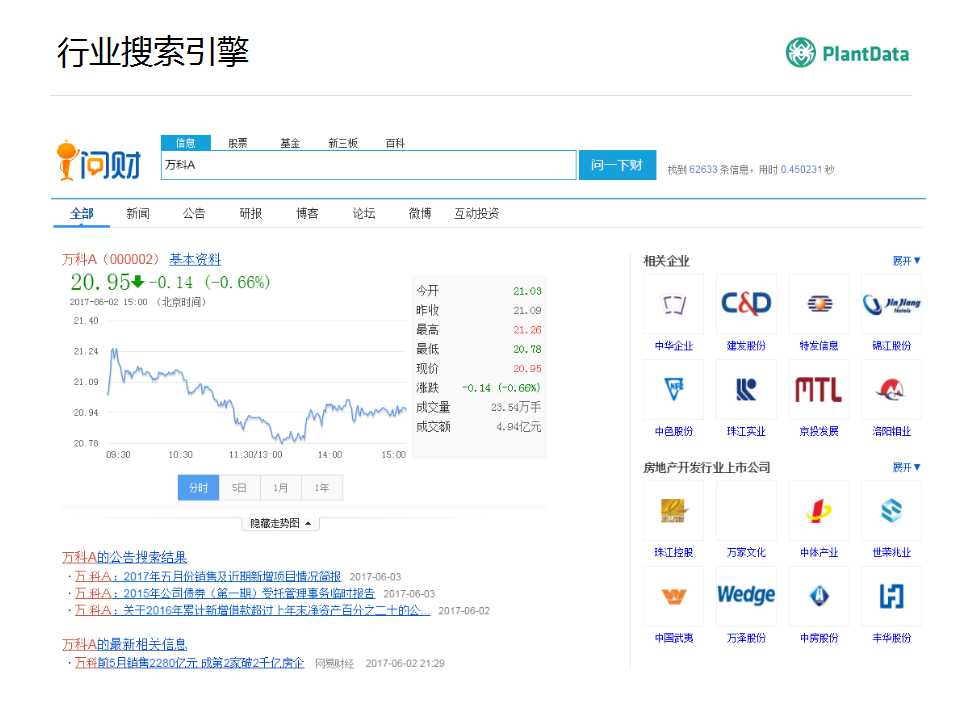
�������������ʲƣ������������“���A”�����ͻ����ȷ�ĸ����㣬��������һ����Ʊ����Ʊ���ע�ľ���������IJ������ʲƻ��Զ��İ����A����ɼ۲��������߸�չʾ������ͬʱ������������A�Ƿ��ز���ҵ�ģ����������·��Ƽ����ز������ҵ�Ĺ�˾��
����֪ʶͼ������ҵ�����һЩӦ�á�
����Ҳ����һЩ̽�����ڴ�Ͷ֪ʶͼ�ף�Ҳ���Ƕ�һЩ������ҵ��Ͷ����Ϣ������“���ִ�”�����Ĺ�˾����“����С�ۿƼ�����˾”������ȥ�ѵ�ʱ�ͻ�ȥ�²��û������ʲô��
��һ�����ĵ�Ӧ�������������¼�����ʷ�����ǻ���һ��ʱ���ͼ�����ʵ���ʷ�����ֳ�����ͬʱ��һ�ҳ�����ҵ�����ǻ���������Ĵ�ʼ�ˣ���ʼ������Щ��������Σ����ǻ�һ��չʾ������ͬʱ����һЩ��ص��ȵ��¼����ţ���Щ����֪ʶͼ����������������Ǵ�����һЩ�仯��
�����������������һ���Ļ��������ʴ�����������֪ʶͼ����һ��Ӧ�ó�����
�Զ��ʴ�
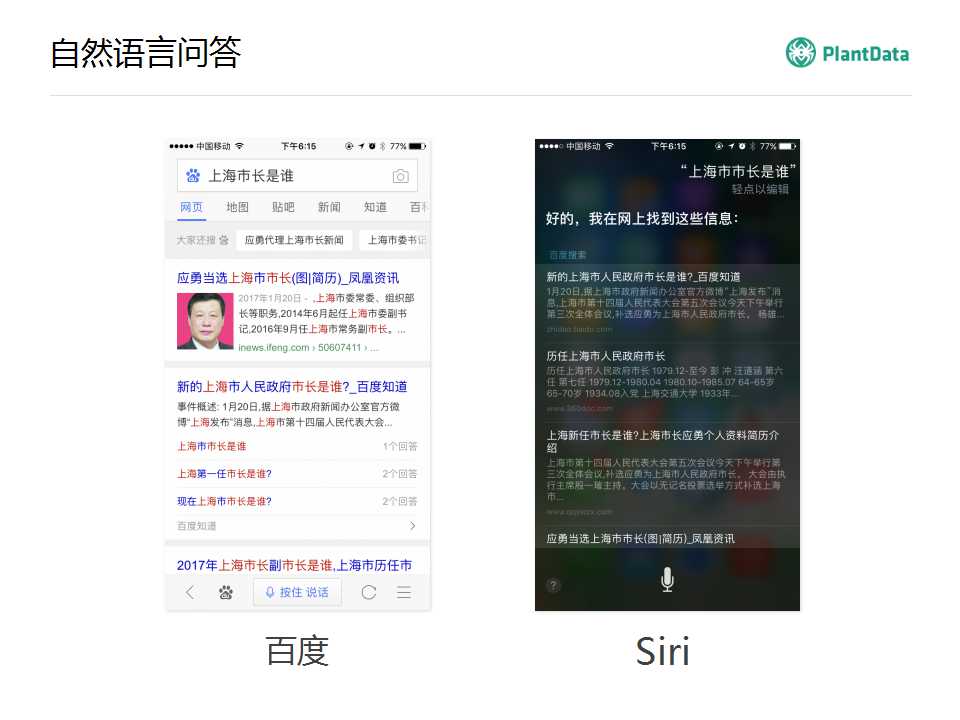
�Զ��ʴ�ĿǰҲ��һ���dz����ŵķ��������������Ӧ����ֱ�ӵķ�ʽ��Ŀǰ������ѧ���绹�ǹ�ҵ�綼������ص��о����������������ӣ�����ǰٶȵĶ��أ��ұ���ƻ����Siri�����Կ�����Ȼ�����ʴ�Ľ����
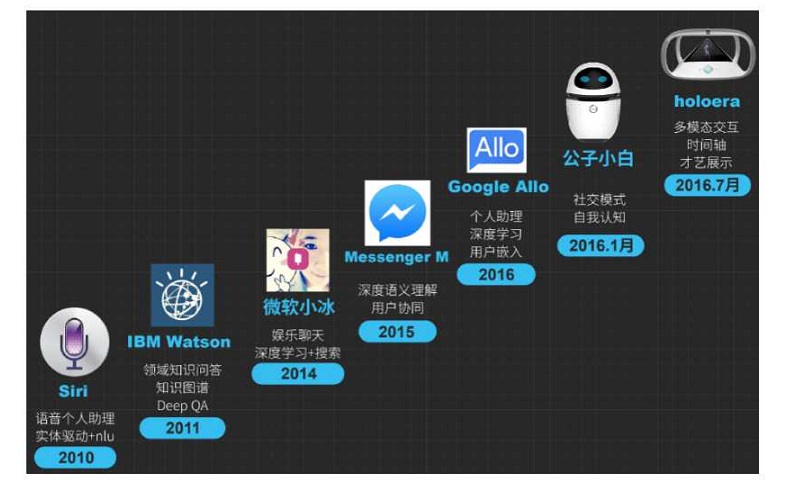
���ڻ���һ���Ƚϻ��������Ƕ�ͯ�����ˣ�������껷���ʦ����PPT�����е�һ��ͼ�����ǿ��Կ�����������˴�10���ʱ��ʼ���У�һֱ�������Ѿ������˺ܶ���д����ԵIJ�Ʒ�����а���Siri��С����IBM Watson������С�ȡ�
ʲô�������ʴ�
�����ʴ���ָ�û�����Ȼ�������ʵ���ʽ�����Ϣ��ѯ����ϵͳ���ݶ�����ķ������Ӹ���������Դ���Զ��ҳ�ȷ�Ĵ𰸡�
������Զ��ʴ�Ҫ�������飬����Ӧ�ÿ��Է�Ϊ���¼��ࣺ
��һ����������죬����Ӧ������С��������С�ף�Ȼ������˽������������������ʹ������Ƕ��غ�Google Allo��������Ϊ����֪ʶ���ʴ𣬱���IBM Watson����ҽ���Լ��ܶ���������������Ӧ��Ӧ�ã����кܶ���ҵ���������ܿͷ�����Ϊ�ͷ�������һ���ȽϿ���Ĺ������������ܿͷ����������ǵĹ�������ʡ���ܶ�������ɱ���
���Ƕ�֪ʶͼ���ʴ���һ��������Է�Ϊ��
���������Զ��ʴ��ض�������Զ��ʴ𣬳������⼯�Զ��ʴ����dz�ΪFAQ��
FAQ�ںܶೡ�������Ѿ��ﵽ�˺ܺõ�Ч�������ǿ۵����ۣ��ڿ���������Զ��ʴ���һ���Ƚϳ����ĽΣ��������ڸ���ɹ������������ض��������棬�ض�������������һ���ǻ�����ҵȥ���������������ʴ��һ�����ࡣ

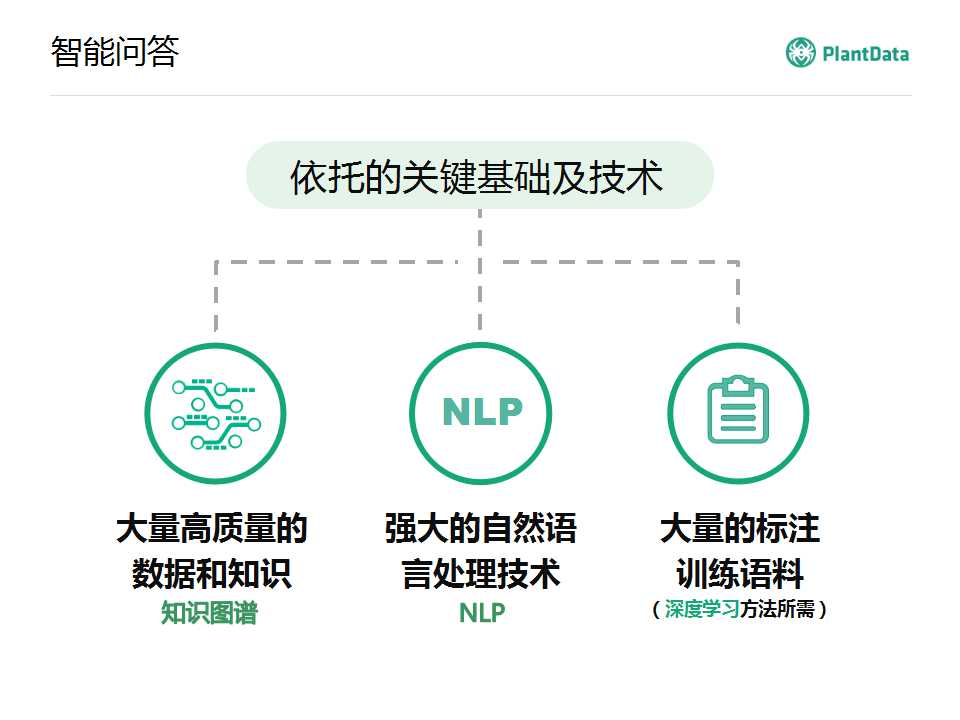
�����ʴ�������һЩ�ؼ��Ļ�����������һ����Ҫ���������������ݺ�֪ʶ�⣬��������ǽ�������Ļ��⣬֪ʶͼ�ף�ͬʱ��������ǿ���NLP������֧�ţ���ҪNLP������������н�����ͬʱ���ӵ�д��ģѵ�����ϵĻ����Ӻ��ˣ���Ϊ�������ѧϰ��һ�����ơ�
������д��ģ���ϣ��������ʴ�ԵĻ����Ϳ����������ѧϰȥ�ṩ���ֶ˵��˵������ʴ�
���������һ���Զ��ʴ�Ļ������̡�
���û����뿪ʼ�����ǵ���������Ȼ���ԣ������ȥ�Ժ�һ��������������н������������Ժ�ͻ�ȥ���������ʵ��ͼ��ȥ�²���Ҫ��ĵ�����ʲô������Ȼ����ݶ�����ͼ�����⣬ȥ��ѯ�ͼ���������ǶԲ�ѯ�ͼ����Ľ����һ����ѡ�𰸵����ɺ�����������ͨ��һЩ������㷨�������ս���������
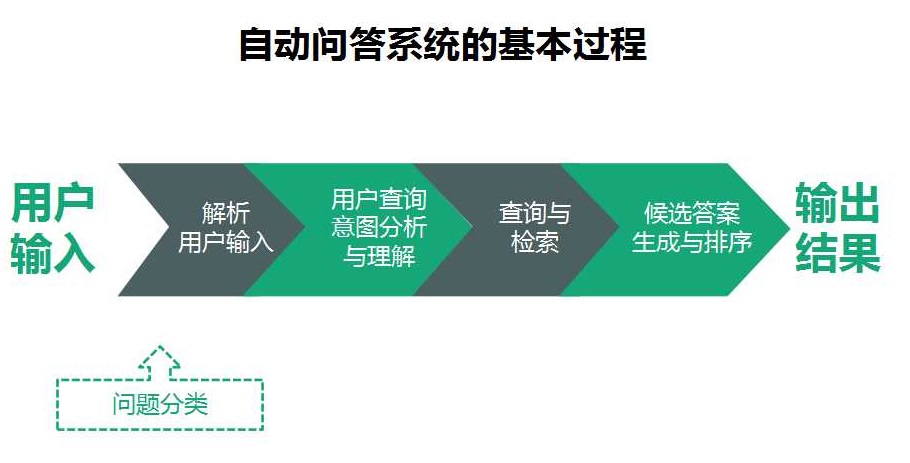
�����ʴ����ڵķ�����Ҫ����ô���ࣺ
��һ���ǻ�����Ϣ�����ķ������ڶ����ǻ�����������ķ������������ǻ��ڹ����ר��ϵͳ������Ȼ���������о��ıȽϻ��һ���������ѧϰ�ķ�����
�������Լ��ַ�����һ�����ܡ�
������Ϣ�����ķ���
�����������Ļ��Ǻʹ�ͳ�ļ��������dz����ƣ��������÷ִʡ�����ʵ��ʶ������NLP����ȥ���ʾ���н������õ��м�Ĺؼ��ʣ���һ���õ�ʵ�壬�õ���Щ�ؼ��ʺ�ʵ��֮����ȥ��Դ������м�����
���и�ȱ�㣬����������������������ڰٶȻ�Google�м������ͻᷢ��һ�����⣬��Ҫ����Ĵ𰸱������ٰ����ʾ��е�һ���ֻ�ʣ����Բ�ȫ�ʷ�����Ի�Ƚϵ͡�
�������֪ʶͼ���Ժ����ǾͿ��Խ��иĽ������Ի���֪ʶͼ����������������䣬�����ʾ���зִʡ�����ʵ��ʶ��֮���Դ�֪ʶͼ������ȥ��������ͬ��ʣ�����ʵ�������ijƺ����Ϳ��Զ��������������䣬ȥ�������ƥ���ʡ�
ͬʱ����������������Ӧ�ö�������һ�����������᪵����⣬Ҳ����ͬһ���ʻ��ַ�������������ͬ�ĺ��塣���Ǿ����ľٵ�һ�����ӣ�����“ƻ��”�������ܴ����ܶණ�������Դ���ˮ����Ҳ�����Ǵ���ƻ����˾��Ҳ���Դ���ƻ����˾��һЩ��Ʒ�����ͨ���ؼ��ּ����Ļ�����ô���Ѷ���Щ������������ϵ����֣���������֪ʶͼ��֮�Ϳ��Դ�ʵ��ĽǶ�ȥ���⡣
������������ķ���
��������dz�ֱ�ۣ������˵�����dz����ƣ����ǰ���Ȼ���Ե�һ���ʾ䣬�����ض���������ԵĹ���ȥ���н������γ�һ������ı���ʽ���õ��������ʽ�Ժ����������ʽ������ȷ��ȥ��������ͼ��Ȼ��Ϳ��Էdz������ת����Ϊһ�ֲ�ѯ���ԣ����ֲ�ѯ���Կ��������ݿ�IJ�ѯ���ԣ�Ҳ�����������IJ�ѯ���ԡ���ȡ����������ݣ���IJ�ѯĿ���Ƿ���ʲô�ط���
���õķ�������������Ϸ������CCG���ķ�ʽ�����������ĵľ��Ǵʻ㣬�������ǻ����벻����Ȼ���Դ���ȥ��ӳ��õ��ʻ㣬Ȼ��������Ĺ������Щ�ʻ���������ϵ���ϣ����յõ��������ʽ��
����������һ���ѵ�ģ�Ҳ�������ĵ���Ȼ���Է������������������ȷ�ʣ����Ѵﵽ��ҵ���õļ���һ��ͨ��������50%���ڣ�����������������������ѵ�һ�����⣬�����������������ͨ�õ��ʴ�ȥ��������ȷ�ʱȽϵͣ����ͨ������������ʴ���һ���Ƚϳ����ĽΡ�
��ôȥ�Ľ���ͬ����������֪ʶͼ�ס�����ͨ�õ�֪ʶͼ�����������ܱ�֤��������������ͨ�õ���������֪ʶͼ��ȥ���ܴ�ĸ��ƣ�����ͨ��������ʱ���������Լ���̽����ʱ�����ض���������ȥ�������ǻ����֪ʶͼ�������ʵ�塢���ԡ�����ȥ����������Ĵʻ�ʵ����н�����ӳ�䣬Ȼ���ٻ���ͼ�ṹ��һ��������ƥ�䣬����൱����ͼ�������ͼ��ѯƥ�����⣬ͨ�����ַ�ʽ�����ǾͿ�����������ķ�Χ���������������Χ�Ժ���Ϊ����֪ʶ�㹻�࣬�������������棬����ͨ�����ǿ��Թ�����Կɿ���֪ʶͼ�ף��Ӷ����Եõ���ȷ�ʱȽϸߵĽ����������ȥ���м������Ϳ��Դ������Զ��ʴ��ȷ�ʡ�
���ڹ����ר��ϵͳ����
�����ַ�������˵�DZȽ����Եģ�Ҳ����������80����õıȽ϶�ġ�
���ַ������ĺô��dz����ԣ���������еĻ�ȷ�ʷdz��ߣ������Ͽ��Դﵽ100%��������ȱ��Ҳ�����ԣ������������Ӧ�õ�����Ƚ϶�Ļ�����ô���϶��Dz���֧�ֵģ���Ϊר��ϵͳ�ķ�Χһ��Ƚ�խ�����������չ�ԡ��ɸ�����Ҳ�DZȽϲ�ģ����Ҫ����һ��ר��ϵͳ����Ҫ���Ѻܴ�ľ��������ַ�ʽҲͨ�����ɸ��ơ�
����ȱ�����ͨ���ԱȽϲ���ܸ��Ǻܶ�Ӧ�ó�����
�������ѧϰ�ķ���
�����������dz��ȵġ����ѧϰ��������Alpha Go�����Ժ���������һ���߷塣��������������磬ѭ��������������صļ�����NLP����Ҳ�õ��˱ȽϺõ�Ӧ�ã���ȡ���˱ȽϺõijɹ�������Ҫ���������Եı�ʾ�����Ա�ʾ�Ϳ�����չ���ʴ����棬����ǰ���ÿһ���ؼ��������������Ե����������ʱ����������ʹ𰸵�ƥ�䡢���ɵ�ʱ�������õ�������˵���Ƕ��û���������н������Դ𰸼�����ѯ���ڽ����Ż�������Ŀǰ�õĽ϶��һ�ַ�����
����һ��ʹ�õķ�ʽ������ǰ���ᵽ��ʹ�����ѧϰȥѵ���˵��˵��Զ��ʴ𣬰�����ʹ𰸾�ʹ�ø��ӵ�������������������Ȼ�������ѧϰ����������ʹ�֮������ƶȣ����ո����𰸡�Ҫʵ�ֶ˵��˵��Զ��ʴ���һ��ǰ�������Ҫ�д��ģ�����ϡ�
�����Զ��ʴ�����ַ�����֪ʶͼ�������еķ������涼�����õģ����Ǹ���һ�£�֪ʶͼ���������Զ��ʴ�����Ĵ��ԣ�
�����Ը���ȥ���û�����Ľ����������������չ�������Ը�����ȥ�����û�����ͼ����“�ַ���”��“ʵ��”��Ҳ���ǵ�ʵ�弶���ȥ���⣻Ȼ����ȥ����֪ʶ��������֪ʶ����֮���㲻�����Եõ������֪ʶ�����ҿ��Եõ���ȵ�֪ʶ��Ȼ���������Ը���ȥ���𰸵����ɡ�
֪ʶ��������˵���ʴ�ϵͳ���“����”��һ�����Ļ��ڣ���ôȥ��ߵģ��Ȼ����ǻ����֪ʶ������ص�һЩ������
���������������ʴ������һЩ̽��������˵�ǻ������������һ���Զ��ʴ�������Ҫ����Ӧ������ҵ���棬���û����뿪ʼ�����ǻ����֪ʶͼ�Ը��ʵ�塢�����Լ�һЩ��ص�����������зִ�ƥ�䣬Ȼ�������֪ʶͼ�������Ԫ�ؽ���ӳ�䣻������һ������������Ľ�������֤��֪ʶͼ�Ľṹ���ر�ǿ���������������������������ʱ������֪ʶͼ������ͼ�ṹȥ�����������⡣
�������������֤����������棬����Ӧ����֪ʶͼ�Ľṹ������˵ʵ������Ե����ӡ�ʵ���ʵ��֮������ӣ����Ǵ������������һЩ���塣
������������Ժ�������������ѯ��ת����֪ʶͼ���Ǵ�����Ӧ��ͼ�洢���棬��������Ӧ�IJ�ѯת���dz����㣻�����ȥ���ݵ���Դ����ȥ���в�ѯ�����շ��ؽ����
�ұ��������ں���֪ʶͼ����������һ��Ӧ�õİ�������������������ڲ����������㣬�������Ƕ��������ʵ��Ľ����������ȥ��������Ľ�����Ȼ����ȥ���в�ѯ�����ո����𰸡�
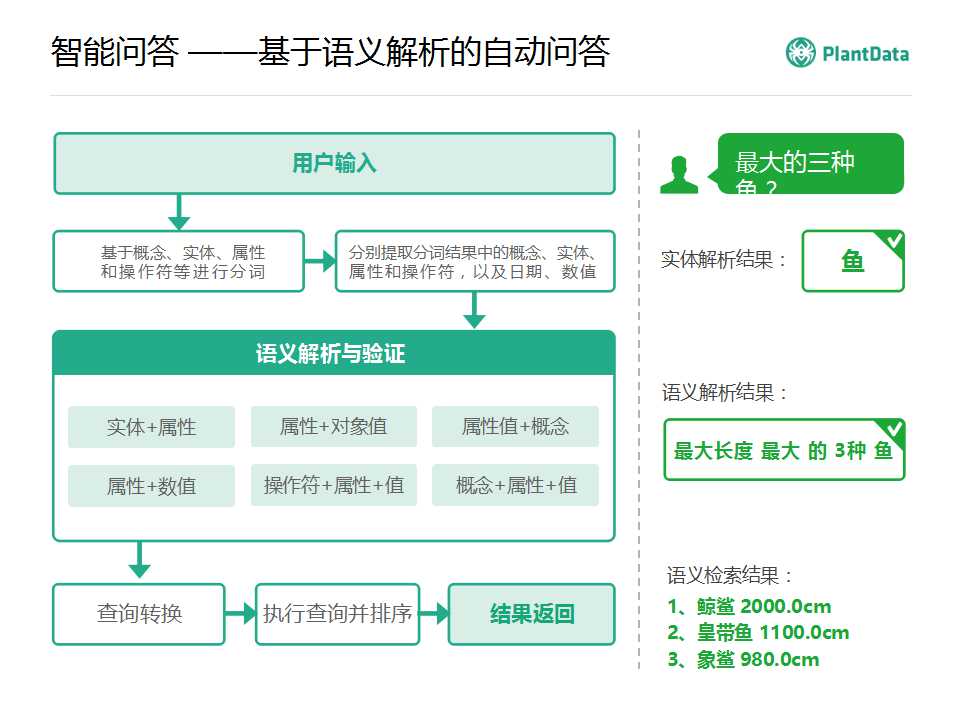
���������Լ��ڻ�������������Զ��ʴ�ϵͳ��������һЩ̽����
�ոհ�֪ʶͼ����õ�����Ӧ�ó�������һ����������һ����������һ�����Զ��ʴ�
���������Ƕ�֪ʶͼ��Ӧ����ص�һЩ������һ��������
֪ʶͼ��Ӧ�ü���������Ҫ�������ࣺ
ͼ�ھ��ͼ���㣻���ӻ���֪ʶ������
֪ʶͼ��֮�ϵ�ͼ�ھ�ͼ���
����ôһЩ�㷨��
��һ����ͼ������֪ʶͼ������֮���������Ϊ��һ�źܴ��ͼ����ôȥ��ѯ�������ͼ��Ҫ����ͼ���ص��Ӧ�õij������б������ڶ�������ͼ���澭����㷨�����·������������·����̽Ѱ������������ʵ�����ʵ��ȥ��������֮��Ĺ�ϵ�����ĸ���Ȩ���ڵ�ķ����������罻����������õıȽ϶ࣻ���������Ⱥ�����������������ƽڵ�ķ��֡�
ͼ�ı���
ͼ�ı�����Ҷ�֪�������ַ�����һ���ǹ�����ȱ�����һ����������ȱ�����������ǾͲ���ϸȥ˵�ˡ��������һ�����ӣ������������ͼ���ֱ��ù�����ȱ�����������ȱ�����ѯ�Ľ����
���·��
���·����Ϊ������������һ���ǵ�Դ���·�����Ľ����¾��Ǵ�һ���������ȥ�������������нڵ�����·����
Dijkstra��ͼ���ᆳ����㷨���㷨��Ȼ�ȽϾ��䣬��������ʵ�м�Ӧ��˵Ӧ�ó����DZȽ��ٵģ��������罻�������棬���Ǻ���ȥ��һ���˵����������˵����·�������Ӧ�õĺ��岻��
�ڶ�������ÿ�Խڵ�֮������·������ͬ��Ҳ��һ���dz������Floyd�㷨�����Ӧ�ó���Ҳ�Ƚ��٣��罻�����м�Ҳ���ٲ�����������֮������·����
���Ǿ�һ�������Ӧ�ó�����Ҳ���Ǹ��������ڵ㣬������֮������·�������Ӧ�ó����ͱȽ϶��ˣ����罻�����������ˣ������Ҫ����ͨ����������֮����й�����
�����ǵ�Ӧ�ó����м�Ҳ�dz��࣬����˵�����ǵ���ҵ֪ʶͼ�����棬����������˾��Ҫȥ������֮�䵽����û�й�ϵ�����������й�ϵ�������һ�����͵�Ӧ�ó�����
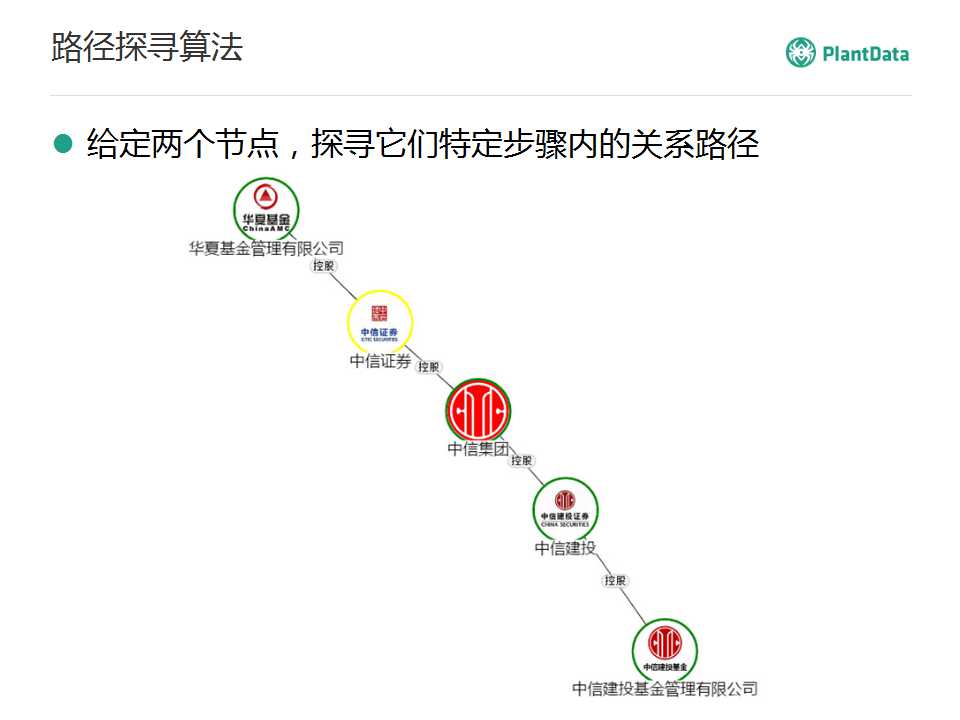
·��̽Ѱ
�ո����ǰ����ͼ���������·���������Ը��������ڵ㣬ȥ������֮�䲻���������·�������Բ�������ҵ֮��5�����ڵ�������Щ��ϵ�������·��̽Ѱ�㷨��Ҳ���Ǹ������������ڵ㣬̽Ѱ�����ض��������浽���ж��ٹ�ϵ������Щ·����
���������ڵ㣬����ڵ�Ҳ��ͬ���ģ�����˵�����ǵĴ�Ͷ֪ʶͼ�����棬����ȥ����Ѷ���ٶȡ����ﹲͬͶ������Щ��˾����Ϳ�����ת����һ��·��̽Ѱ���㷨��Ҳ���Ǹ�����������˾������ȥ�����ض��IJ������棬��������Щ·����ϵ��������ֱ��Ͷ�ʻ��Ǽ��Ͷ�ʣ���������Щ��ͬ��Ͷ�ʡ�
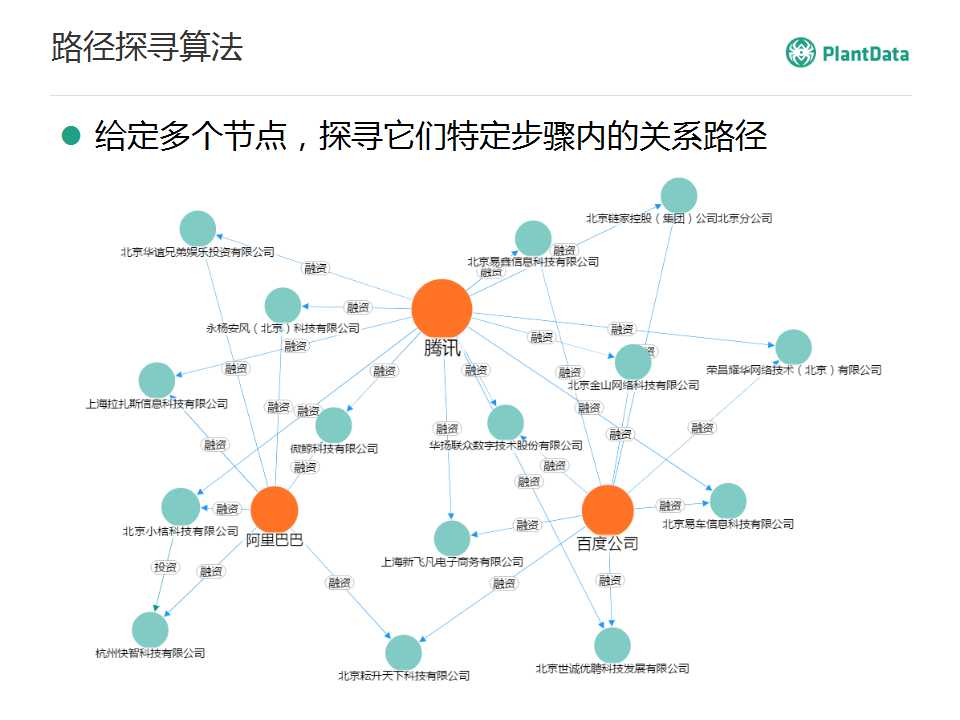
Ȩ���ڵ�ķ���
�ȿ�Ӧ�ó����������罻�����������Ӧ�ö�֪���������и��ܳ�����Ӧ�ó��������罻�������Ȩ�����������Ҳ�������罻����������Щ���DZȽ���Ȩ���ģ���Ȩ����������˵����˿�����Ȩ����������Щ�ˣ������ض�������������Ȩ����
����һ�£���֪ʶͼ�������м䣬��ôȥ�����ڵ��Ȩ���ȣ��ҵ������Ȩ���ڵ㣬�������㷨�ͱȽ϶࣬������㷨�����������������Page Rank������˵������һ���ͶƱ�Ļ��ƣ����ȥ����ÿ���ڵ��Ȩ���ȡ�
����һ���ǻ��ڽڵ�������Լ��ڵ�֮���ϵ��һ�ֶ�����������֪ʶͼ��ÿ���ڵ�����Լ������ԣ�ͬʱ���к������ڵ�֮��Ĺ��������ǿ��ѽڵ����Ժ�ϵ����������γ�һ�ֶ�����������������
�ڴ�Ͷ����֪ʶͼ�����棬һ��Ӧ�ó�������ȥ�ҵ������Ȩ��Ͷ�ʻ�����ͬʱ����ȥ�ҵ���Щ����DZ���Ĵ��¶�����˾��
��Ⱥ�ķ����㷨
�����ȿ�Ӧ�ó��������罻�����У����Dz������ǶԸ��˸���Ȥ��������֪���������У�����ЩС��Ⱥ�塣
���罻�����д���һЩ��������������ڶ��ض��������Ȥ��Ⱥ�壬�������Ǵ�Ҷ�֪ʶͼ����Ȥһ��������Ҫ���罻�������ҵ���֪ʶͼ����Ȥ����Щ����������Ⱥ�����㷨��һ��Ӧ�ó�����
������һ�£������Ǵ�֪ʶͼ�������м䷢����һ�����߶���Ƕ����ƽڵ����Ⱥ������Ҳ�Ƚ϶࣬���������г������㷨����һ����ͼ���澭���������㷨������һ���ո��ڼ���Ȩ���ڵ�ʱʹ�õķ������ƣ����ǻ��ڽڵ�����Ժͽڵ�֮��Ĺ�ϵ�γɶ�����ȥ���о��࣬�Ӷ��ҵ������Ⱥ�塣
����ҵ֪ʶͼ�����棬���ǿ���ȥ�ҵ�ȫ����ǧ����ҵ����İ���ϵ����Ѷϵ��Ҳ������Щ�ǰ���Ͷ�ʵģ��������Ȥ��һЩ��˾��
���ƽڵ�ķ����㷨
����������ҵ֪ʶͼ��ʱ����һ����ҵ���Ѿ���һЩ�ͻ��ˣ������ܻ�ϣ���ҵ����ƵĿͻ�����ô���ǾͿ���ȥ�ҵ��������пͻ����Ƶ�һЩ�ͻ�����������ƽڵ㷢�ֵ�һ��Ӧ�ó�����
�Ӻ�����֪ʶͼ���м�ȥѰ�Һ���֪�ڵ����ƵĽڵ㣬���������֣�
��һ�����ǻ��ڽڵ������ȥ�飬����˵������ҵ���Ϳ��Ը�����ҵ��Ʒ������ȥ�ң����ǻ����Ը��ݽڵ��Ĺ�ϵȥ���㣬��Ϊ��ϵ������һ�����������������ǿ���ͨ�����ֹ�ϵ������˵�����ڵ�֮��Ĺ�ϵͼ�dz����ƣ���ôҲ����һ���̶ȵ����ƣ��������û�ϵķ�ʽ���ѽڵ�����Ժͽڵ�Ĺ�ϵһ��ȥʹ�á�
��������һ��Ӧ�ó�����������ר��֪ʶͼ������ȥѰ�����Ƶ�ר����
֪ʶͼ�Ŀ��ӻ�
���ӻ�Ӧ��˵�ܺ����⣬������������ά���ٿ���Ķ��壺���ӻ������ü����ͼ��ѧ��ͼ��������ؼ�����������֪ʶ����Ϣ���ͼ�λ�ͼ������Ļ��չʾ��ͬʱ����һ���������Ҫ���û����н�����
��������������㺬�壬��һ������Ҫת����ͼ�ڶ������ǽ�����������嵽����˵�Ѿ��е��ʱ�ˣ����ڲ������Ǽ�������ܶ������ƶ������豸���п��ӻ�������
���ӻ����ǿ������������ܣ�
��һ��������Ϣ�ļ�¼����������������Ϣ�ij��֣�Ҳ��������Ϣ�ļ�¼��ͬʱ��֧�ֶ���Ϣ�������ͷ�����������ǰѿ��ӻ����ĺã����Դ����ݵĿ��ӻ������ҵ��ܶ��ϵ���ɣ��Ӷ�����һ���������ͷ���������������Ϣ�Ĵ�����Эͬ������֪ʶͼ���ӻ��Ķ�����ܡ�
����֪����һ��ģ�ͣ���DIKW��Ҳ�������ݡ���Ϣ��֪ʶ���ٵ��ǻۡ����ģ������Ӧ�÷dz���Ϥ���ӵײ�����ݿ�ʼ����һ�����������γ���Ϣ��Ȼ���ٽ��г�ȡ�γ�֪ʶ����֪ʶ����������ܶ��Ӧ�ã�����˵����������˵���ڵ��˹����ܣ�������ǻۡ�
���嵽���ӻ����棬����Ҳ��������ȥ���࣬�����ݵĿ��ӻ�������Ϣ�Ŀ��ӻ����ٵ�֪ʶ�Ŀ��ӻ�����Ȼ��������ǻ۵Ŀ��ӻ���������ӳ��������ѣ�������ǽ���Ͳ�ȥ������
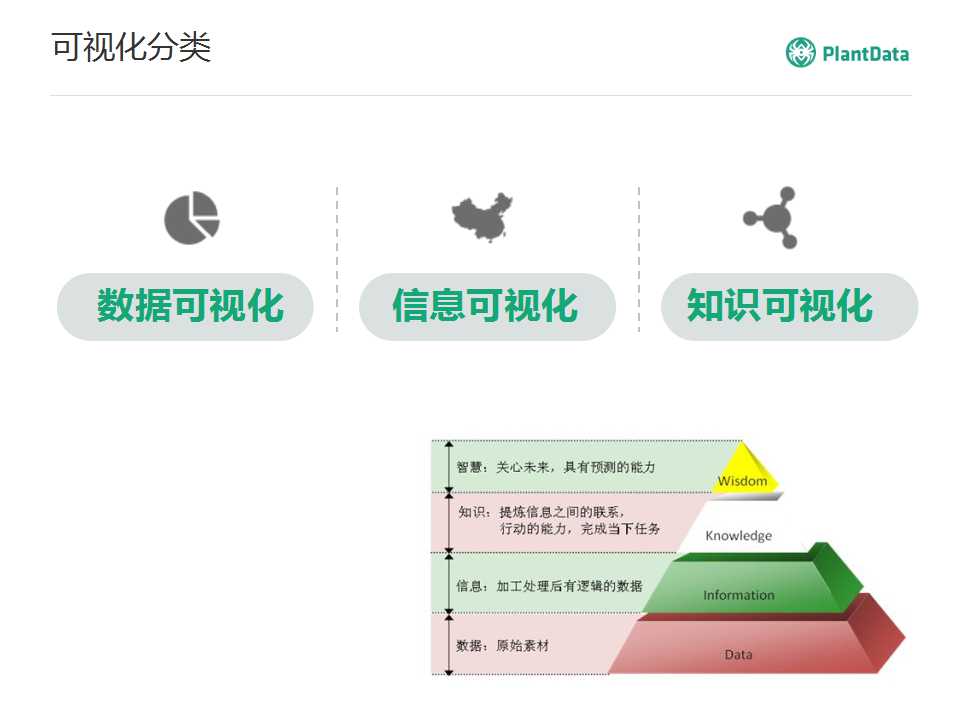
�ȿ����ݿ��ӻ�������Щ���͵����ݣ���һ�����Ǽ�¼�͵����ݣ�ʹ�ù���ϵ�����ݿ�ͻ������������кܶ��¼�͵����ݣ�Ȼ���й�ϵ�͵����ݣ��������ǵ�֪ʶͼ�ף�����һ�ֹ�ϵ�ܼ��͵����ݣ�Ȼ����ʱ̬���ݡ��ռ����ݡ�
ʲô�����ݿ��ӻ����������Ƚ����ۻ����������ݿ��ӻ���������ȥ���н��ͣ����Ӧ�ö�֪�������ǰ����������һЩ��Ϣ�����壬��ôȥ��һ����ʽȥ���г�����ȡ���γ���ϢȻ������Ӧ�����ԡ�����ȥ������棬�������ݿ��ӻ���
���ݿ��ӻ������кܶ����۵��о��ͼ�������������ʱ���ϵ���Ҳ�ȥ��ϸ�Ľ��ܣ���Ҹ���Ȥ�Ļ�����ȥ������Ϊ���ڵġ����ݿ��ӻ��������������ӻ����˷dz���ϸ��������
Ȼ������Ϣ�Ŀ��ӻ���֪ʶ�Ŀ��ӻ���Ӧ��˵��Ϣ��֪ʶ�Ŀ��ӻ���һ���̶��Ϻ���ȥ����ֱ�ӵ����֣���Ϊ��Ϣ��֪ʶû���ϸ�Ľ��ޡ���Ϣ���ӻ����о����ģ����ֵ��Ϣ��Դ�ij��֣���������Ҫ��Ŀ����ǰ�����ȥ����ͷ������ݡ�
֪ʶ���ӻ���Ҫ��������ͱ�ʾ����֪ʶ��ͼ����ͼ��ͼ�ε��ֶ�ȥ�������ҪĿ����������֪ʶ�Ĵ���ʹ��ݣ�����������ȥ��ȷ���ع��������Ӧ��֪ʶ��
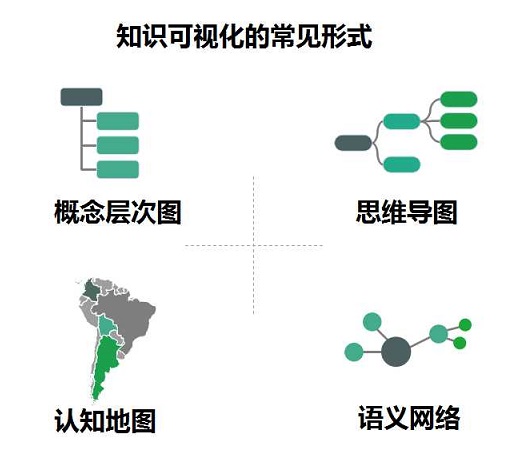
���������ǿ�һ������֪ʶ���ӻ���ʱ������Щ��������ʽ���������г�����ֻ��һ���֣�����˵��֪ʶͼ�����������и������IJ�Σ�һ��ֱ�۵ķ�ʽ�����ø���IJ��ͼȥ����֪ʶ�Ŀ��ӻ����ڶ��־�����˼ά��ͼ����ʽ��ͬʱ���ǻ�����ȥ����֪�ĵ�ͼ������������������ķ�ʽ��֪ʶͼ����������ԭ��̬������������ʽ���������ġ�
��ࣺ����֪ʶ��